This short series of blogs chronicles the bare-bones required to conduct a basic form of textual analysis on corpora of Japanese tweets. Examples of similar tutorials on the Internet are numerous,2 but less so are accessible beginner tutorials guiding the reader throughout the processes of:
- setting up the initial technical environment,
- compiling corpora of clean, processed data, and,
- adding a visual, quantitative element to any qualitative reading of that text, by utilization of textual analysis tools tailored for Japanese content.
This series is therefore primarily intended for undergraduate and graduate students whose topics of research include contemporary Japan or its online vox populi, and want to strengthen their existing research (such as an undergraduate thesis or term paper) with a social media-based quantitative angle.
Keeping in mind that many of those situated in the humanities might experience an initial technical hurdle, this first blog will focus primarily on the how, rather than on the why of doing Twitter-based research, by detailing the minimal necessities for getting up and running — supplemented by a brief optional, technical explanation for those who are interested. With this first blog, the reader will thus concretely:
- Set up a Twitter Developer account and obtain Twitter credentials,
- Set up a Python development environment,
- Run tailored Python scripts to build datasets of tweets, based either on keywords or on the tweet history of particular users
- Use Python for preprocessing the dataset into a usable corpus.
This first blog assumes that the reader has already chosen a topic or target of analysis for which a form of Social Network Analysis (SNA) or content analysis of Twitter data is well-suited. A more thorough epistemological introduction to the why, what, when and who of SNA, as well as further recommended reading, will follow in the future. Suffice to say, the technical ease of working with the Twitter APIs, as well as the global-spread use of Twitter (roughly half a billion tweets are sent every single day, with Japanese per capita usage ranking particularly high), offer an excellent introduction to getting acquainted with SNA through practical, real-life examples.
Set-up
It must be emphasized that the field this tutorial roughly falls under, Digital Humanities (DH), is extremely broad; and understanding the various possibilities DH offers, as well as when and how to apply those, have their own intricate challenges. Within the scope of our brief tutorial series, however, the initial technical hurdles of setting up a proper technical environment and just getting scripts running will probably be the most challenging for most readers. The set-up and approach we will be applying throughout this series might seem daunting at first, but as of writing, there is no free alternative with a graphical user interface that offers as much control as doing things manually would.
Twitter API credentials
APIs (Application Programming Interfaces) are pieces of code that permit cross-platform and cross-programming language communication between different software. A web-application, a desktop application or a simple script of code (such as the ones in our article) might access an API in order to exchange (retrieve, create, update or delete) information. Mobile versions of Twitter (Android, iOS), for example, are relatively simple applications that might access the Twitter API to get tweet data from its online servers to display it on-screen, or instead sent and save a newly written tweet. This kind of interaction between different applications, written in different programming languages, is everywhere: even a simple retweet button on a blog article, or a Buzzfeed news article peppered with a bunch of relevant tweets, rely on those Twitter APIs.
Like many other large social media platforms such as Facebook and YouTube, Twitter has an extensive list of APIs made available to developers, researchers and market strategists alike. The most extensive ones are limited to expensive Premium and Enterprise editions targeting commercial enterprises, but, while undeniably limited, the free standard APIs and its Terms of Service (ToS) do permit us a certain degree of data accumulation sufficient for our goals.
Note
There are some pitfalls that must be noted in regards to the limitations of the free-to-use Twitter APIs. None of the methods provided below permit the collecting of an exhaustive collection of tweets. Instead, queries will be executed against a sample of the global total amount of (historical) tweets.3 Therefore, any conclusions drawn based on the amount of tweets per timespan will be estimates rather than absolutes. Moreover, due to the time restraints of the Search API (7 days), ad-hoc research of older phenomena is nearly impossible. Depending on the scope of the search query, the Search API and Timeline API in particular could yield more accurate results than using the Streaming API does, however.4
Before we are able to begin, however, we should first apply for a Twitter developer account and obtain several credentials required to access those Twitter APIs. Open the Twitter developer page (if you don’t yet have a Twitter account, you will have to create one now) and click on Apply for an account.

Throughout the next few screens, select Doing academic research → verify your personal personal information (if you haven’t do so yet, you will likely have to verify your cellphone number) → describe your intended use → review your application → accept the Developer Agreement → click Submit Application.

Your application will be judged in-person based on your Intended Use and should be well thought-out. I have written a brief example—for your reference only—, as to how you might approach this, in the screenshots below.
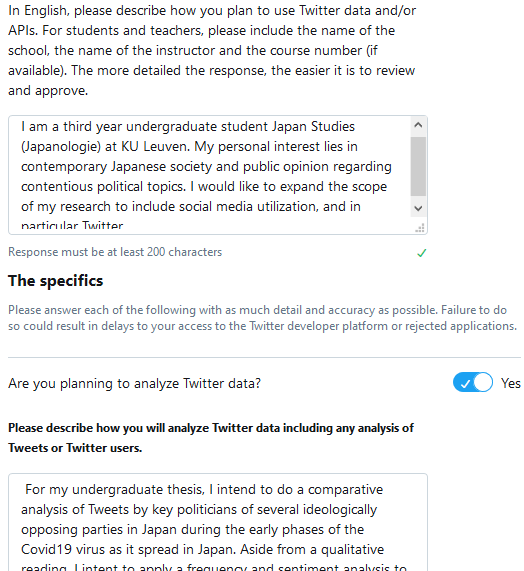
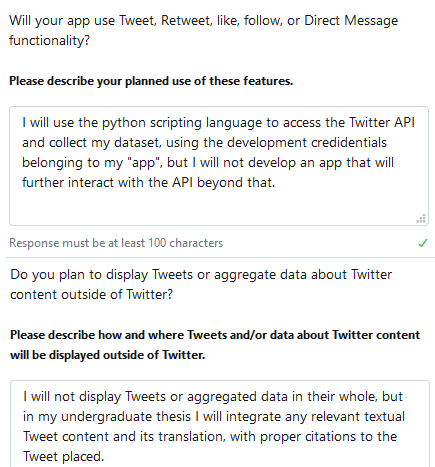
Upon receiving a confirmation of approval (an application is usually approved or denied within a matter of hours), head to the Apps management screen → click Create an app and fill in the required information: an ‘app’ name, brief application description, Website URL, and information regarding how your application will be used. Again, something similar to what is written in the screenshot below should be sufficient for your description. Moreover, the field how it will be used can repeat what was written in the previous application (it is not required to wait for further external approval after creating an ‘app’, so this step is less important). Neither is it important to have a personal website; it is fine to substitute this with an URL to your Facebook, LinkedIn or Twitter profile.

Next, click on the details button for the new ‘app’ and open the Key and tokens tab. Generate Consumer API keys and Access token and access token secret keys, and note these down in a separate file. They are required to connect to the Twitter API through our Python scripts after we have finished our set-up.
Python
Although there are plenty of other programming languages with which we might access the Twitter API for similar results (such as Java or Ruby), in this series of blogs we will use the easy-to-read, well-documented scripting language Python. Python (along with the statistical research language R) has, due to its extensive library of third-party modules, become somewhat of a de facto lingua franca within the (digital) humanities. Within DH, its usage covers anything from data processing, visualization and chore automation to machine learning, Natural Language Processing (NLP) and general linguistic analysis.
Note
It is recommended to follow a brief, optional tutorial.5 Python is relatively easy to learn and doesn’t require any prior knowledge of programming.
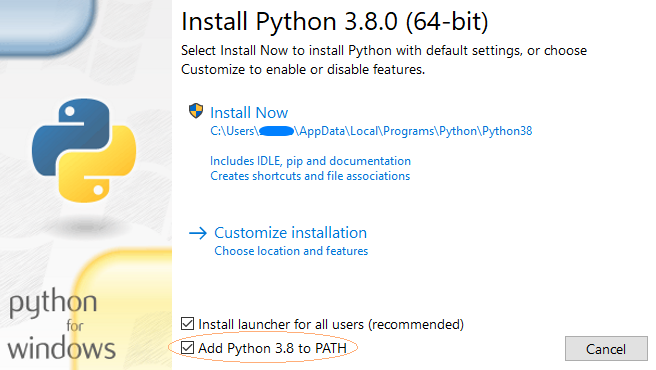
Now head to the Python homepage and download the latest installer version matching your operating system. Recent installers will already be packaged together with necessary add-ons such as pip, a Python package manager for installing custom packages. Make sure to check the Add Python 3.x to PATH check button before proceeding.6
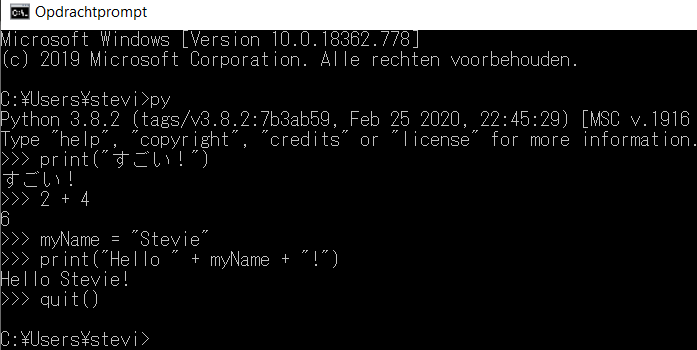
Next, open the Windows command prompt (or the Terminal on Mac OS X).7 To do so on Windows, press Win+R , enter cmd and press Enter.8 Now input python (or its abbreviation py) and press Enter again. Given that the installation went off without a hitch (and that the python executable was successfully added to your PATH variable), this should open the python interpreter as shown in the screenshot below. Play around a bit and input quit() to exit the python interpreter environment.
Finally, we will need to install tweepy, a Python package required by our example scripts in order to simplify our access to the Twitter APIs. Input pip install tweepy to install Tweepy and any dependent packages.9
Accumulating Data
Having set up our development environment, let us now dive into some working examples:
- Copy and paste the desired script(s) below in a text editor of choice,10 select save as and save them with a suitable name with the
.pyfile extension (python files)) in an easily accessible folder (e.g. save the first script asaccount_scraper.pyinc:\python_examples\). Alternatively, you could also download them from this article’s corresponding GitHub page. Don’t forget to replace the placeholder Twitter API credentials (####) with the credentials obtained earlier. - Open the command prompt again. Navigate to the folder containing the python script(s) you have just saved (e.g. use the command cd to change directories:
cd C:\python_examples\). - Run the python script by invoking the name you saved it by, using the python command and the name of the query (either the search query or the name of the target Twitter profile, e.g.
python python_twitter.py poppestevieorpy python_search.py poppestevie). - Pressing Ctrl+C in your command prompt at any time will cease the process. Due to the API limitations, the account API script will finish in a matter of seconds, while the real-time streaming API example will run until the process is terminated and, depending on the popularity of the search query, the historical search API script could run for over a day despite a hard limitation of 7 days.
- The APIs return tweets matching our search queries as unstructured data formatted in JavaScript Object Notation (JSON, a lightweight data-interchange format).11 Our script saves those to a valid JSON formatted file in a ‘results’ subfolder (e.g.
C:\python_examples\results\.12
Note
When encoding to UTF8 is enabled, Unicode characters (such as Japanese characters or emoji) and other characters that fall outside the ASCII range are, by default, escaped (e.g. 🤷 → ‘\u1F937’). This is a common practice taken to avoid data mangling among legacy systems, and is far more memory effective due to the large size of Unicode characters (which are up to 4 times larger than their ASCII representations). The scripts on these pages, however, bypass this behavior with the ensure_ascii=False argument.
Datasets that are expected to contain several hundreds of thousands of tweets are recommended to have that argument set to True, as such datasets will easily take up to several gigabytes of disk space. Decoding texts to their actual Unicode value is, in those cases, best kept on a need-only basis during the preprocessing phase.13
By Account: Twitter REST API
Our first example script collects tweets posted by specific Twitter users, up to the most recent ~3200 tweets posted by those accounts (a limitation inherent to the Twitter API itself, which cannot be easily bypassed).14
In essence this script uses Tweepy’s pagination method Cursor to iterate through the target’s timeline, 200 tweets at a time (the maximum amount permitted per access call it makes to the Twitter GET API). Objects are returned as dictionaries of JSON objects, which are iterated through and written to a new, JSON-compliant file (e.g. poppestevie_search_tweets.json).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | |

By keyword
The following two scripts will accumulate tweets based on one or several search queries. The first second example collects tweets from the existing pool of tweets up to about a week prior to running the script, while the second script opens a direct stream to filter incoming content based on the required keyword in real-time.
Note
If you have not formerly worked with the command prompt in Windows, inputting Japanese or other non-western characters (as a search query, for example) will likely result in gibberish. The easiest solution is to change the display font of the command prompt to one that contains all Unicode characters (right click on the title bar → settings → font → select a font such as MSゴシック).
Historical Search: Twitter REST API
Similar to our previous example, this script relies on Tweepy’s Cursor pagination; collecting approximately 100 tweets per access call and writing these to local files as valid JSON. In order to both prevent crashes caused by a memory leak in Tweepy’s pagination method and in order to keep the file size of our JSON files manageable (particularly trending topics might return up to millions of of results over the timespan of many hours running this script, taking up several gigabytes worth of disk space per single file), results are split over different files by an arbitrary number of tweets per file (defaulting to 10 000 tweets, set in line 11).
Since this script runs until either the imposed API limit of 7 days is hit or the extent of all relevant tweets within the Twitter sample are collected (which could take up tens of hours depending on the popularity of the queries), this script can therefore be ceased mid-process by pressing Ctrl+C within the command prompt the script is currently running in.
As is well-documented on Twitter API’s documentation, using the Application only authentication instead of user authentication permits us a much higher amount of requests within a single window of 15 minutes; translating to a faster and more maintainable approach to data-mining historical tweets (roughly 100 tweets x 450 access calls per 15 minutes, for a total of roughly 180 000 tweets per hour).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 | |

Note
If we wish to resume this process starting from where we left off, we might do so using the max_id argument during our Search API access call (which can be set in line 12). Simply replacing None with the tweet ID of the last JSON object in our previously compiled JSON list of results will do the trick. Likewise, we could do the same, using since_id (line 13), to collect tweets over a longer period of time (by taking the tweet ID of the first object in the last compiled JSON file as the entry point).
If we intent to further limit the requested tweets to a particular language, we could also optionally filter our results by setting an language argument (line 14) for our access call: e.g. “language = 'ja'”. It is perfectly possible to filter by several different languages, as well (e.g. “language=["ja","en"]”). Using a filter to limit tweets by location, however, is not recommended due to the limited amount of Twitter accounts that accurately add such information.15
Finally, it might be worthwhile to look into the Twitter API documentation in regards to filtering incoming tweets. If we intend to filter out retweets, for example, we could further adjust our script (line 63) by changing “q=search_query” to “q=search_query + " -filter:retweets"”. Moreover, in order to search by multiple queries, we could just input several queries or use the logical operators OR in-between (e.g. “py python_twitter_stream.py "#corona #covid19"” for tweets containing both, or “py python_twitter_search.py "#corona OR #covid19"” for those containing either. Don’t forget to enclose the query in [] brackets, however!
Real-Time: Twitter Streaming API
Unlike the previous two examples, the following script does not pull data from a RESTful API but creates a listener that is perpetually connected to the Twitter Streaming API (referred to as the firehose, limited to about ∼1% of incoming Twitter traffic). It signals to the API which queries to filter by, upon which the Twitter API pushes back all matching incoming tweets.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | |
Note
If the reader intents to limit the requested tweets to a particular language, they can impose a filter by editing the language variable (line 16) to the intended language (e.g. “language = 'ja'”).16
Data Processing
By now, we should have one or several files containing raw tweet data formatted in JSON. opening one of those files with our text editor of choice permits us a closer look at the skeleton of such tweet objects. As seen in the example below, each single tweet contains a large amount of meta information (the Twitter Developer page offers a brief structural overview of each field in a JSON tweet object), not all of which might be relevant to us. The following fields are some that might be immediately relevant to us at this stage:
“created_at”: “UTC time when this tweet was created.” “id”: “The integer representation of the unique identifier for this tweet” “text”: “The actual UTF-8 text of the status update. “ “lang”: “Nullable. When present, indicates a BCP 47 language identifier corresponding to the machine-detected language of the tweet text” “user” → “name”: “The name of the user, as they’ve defined it.” “user” → “screen_name”: “The screen name, handle, or alias that this user identifies themselves with. “ “user” → “location”: “Nullable. The user-defined location for this account’s profile. Not necessarily a location, nor machine-parseable. “

For this tutorial, the reader will mostly likely require only one or several elements of each tweet, such as the text, time-stamp, and user-name. It is generally best practice to save only the data required, and in that case the above scripts could have easily been edited to do so instead of returning unnecessary large JSON dumps. It could be argued, however, that due to the volatile state of data mining on Twitter, it is still beneficial to have an untainted and complete copy of the data we will be working with. Data seemingly unnecessary at first glance might turn out to be useful halfway through your writing process.
For that reason, we will use the complete JSON dumps acquired through the methods above to build the processed sets necessary for our analysis. With preprocessing, this blog post thus actually refers to the process of removing irrelevant data and any other form of noise until we have obtained exactly what we need.
Note
During this phase, it is further worthwhile to think about how to deal with the other contextual data surrounding each tweet. What about the attached media (URLs, images, videos or sound bites)? How does the tweet fit within a larger thread of conversation? what should we know about the original of retweets or quotes? What about shortened URLs in retweets or quotes? Is the tweet still relevant to our research if it was mined because the full URL of a retweeted tweet contained a matching keyword? Especially for larger datasets, it is important to remove ‘noise’ (e.g. irrelevant tweets and other data) to ensure more precise results.
OpenRefine (optional)
The final section of this article provides another Python script for preprocessing any obtained tweet data to something we can actually use for further analysis. Optionally, we might also install the data cleanup and transformation application OpenRefine.
Although the most clear cut way to obtain data to one’s own needs would be to alter the python scripts provided in this article (Python really is a fairly straightforward programming language), for those who are turned off by the prospect of editing code, the graphical interface of OpenRefine might offer some respite. Moreover, for those collecting data written in different writing systems (such as Japanese), OpenRefine’s data cleanup functionality might turn out particularly useful when dealing with file conversation (e.g. to older versions of MS Excel).
Again, it is recommend getting a bit acquainted with the application. Programming Historian (an open-source and open-access journal of peer-reviewed technical tutorials for those in the humanities) offers a useful introductory guide.
Preprocessing with Python
In essence, the script below is a simple parser that loads the content of the JSON files generated through the above methods and saves several relevant fields (such as the tweet text content, its hashtags and date of creation, as well as basic information pertaining the author) of each tweet in a new CSV file.17 This script serves as a basic skeleton that can be edited to include or exclude desired fields,18 or could be used for further preprocessing (such as cleaning the textual content of URLs or stop words).
As of late 2017, Twitter doubled the allowed character size, which particularly benefits tweets written in Japanese. This script always takes the most complete data (such as the full_text or extended_tweet field), in case the tweet content is longer than 140 characters. Nevertheless, a retweet of a message that exceeds the 140 character length will still get cut off in the JSON Twitter’s APIs return, potentially losing user mentions or hashtags in the process and significantly messing with our metrics. This is not optimal, as the Twitter API will still return search results based on keywords that might have been cut off. To remedy this, the script will reconstruct the retweet based on the content, hashtags and other entity information from the original tweet.
Of final note is the addition of simple helper method for converting the time of creation (in standard UCT) to a ISO 8601 compliant format, another international standard for exchanging date/time-related data.
In order to run the script below, we will again invoke the script using the command prompt. This script expects one argument: the name of our target document (excluding its .JSON file extension, e.g. “py python_parse_tweet.py timeline_tweets_abeshinzo_20200510_211848”).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | |

Note
Spreadsheets such as OpenLibre have strong CSV support. MS Excel versions prior to 2019, however, has some issues with handling newlines, which will most likely mess with our data structure.19 If working with such versions of Excel is a must, the easiest option for dealing with this problem is to import the CSV in OpenRefine (as seen in the screenshot above) and export as Excel file.
Wait! There is more!
This brief tutorial outlined the bare necessities to accumulate tweets, either in real time or historical, based either on user profiles or on particular keywords, using the Python scripting language and several working example scripts. Furthermore, this tutorial outlined a basic method for preprocessing those results into a viable dataset suitable to apply methods of quantitative analysis on. Using a preprocessed CSV generated through the steps taken above, the next guides in this series will cover existing tools and methods that may assist the reader in strengthening their topic of research with a Social Media Analysis angle.20
- A
QuickGuide to Data-mining & (Textual) Analysis of (Japanese) Twitter Part 2: Basic Metrics & Graphs - A
QuickGuide to Data-mining & (Textual) Analysis of (Japanese) Twitter Part 3: Natural Language Processing With MeCab, Neologd and KH Coder - A
QuickGuide to Data-mining & (Textual) Analysis of (Japanese) Twitter Part 4: Natural Language Processing With MeCab, Neologd and NLTK - A
QuickGuide to Data-mining & (Textual) Analysis of (Japanese) Twitter Part 5: Advanced Metrics & Graphs
On a final note, it is my aim to write tutorials like these in such a way that they provide enough detail and (technical) information on the applied methodology to be useful in extended contexts, while still being accessible to less IT-savvy students. If anything is unclear, however, please do not hesitate to leave questions in the comment section below.
-
Still image from the 2012 Japanese animated film Wolf Children by Mamoru Hosoda, used under a Fair Use doctrine. ↩
-
Moreover, the majority of general tutorials found online relied on dated methods and did not take into account recent Twitter changes such as extended length of tweets or quotes. ↩
-
Unfortunately little information is available concerning to how Twitter samples this data. While Twitter, by design, has a particular sociocultural demographic that might not not be fully representative of a greater offline public sphere, even conclusions regarding Twitter usage itself cannot in good faith be called scientifically proof as long as there is not sufficient knowledge on the way Twitter handles its sampling methods. ↩
-
Several attempts have been made to increase sample size and accuracy. One of such, focusing on building a dataset representative of the Japanese Twitter public sphere, is: Hino, Airo, and Robert A. Fahey. 2019. ‘Representing the Twittersphere: Archiving a Representative Sample of Twitter Data under Resource Constraints’. International Journal of Information Management 48 (October): 175–84. https://doi.org/10.1016/j.ijinfomgt.2019.01.019. ↩
-
This blog recommends Automate the Boring Stuff and the interactive Computer Science Circles or its video series Python from Scratch. Earth Data Science has great tutorials as well. ↩
-
PATH is an environmental variable; doing this will allow us to run the Python compiler from command line without having to manually locate its executable. ↩
-
This tutorial was written with PC users in mind but won’t differ that much for other platforms. ↩
-
Or, I mean, whatever method you personally prefer. ¯\_(ツ)_/¯. ↩
-
If you get a message that pip is not a recognized command, you will either have to manually install pip or add the path of your existing pip installation to your PATH variable. ↩
-
I personally use Sublime Text 3 and Atom looks pretty great as well, but for the sake our tutorial, even notepad is sufficient ↩
-
A standard for cross-platform changing of data. Data and its meta-data are represented by key-value pairs: e.g.
“{"first_name" : "Stevie", "last_name": "Poppe"}”. ↩ -
Technically, this will return a file of comma-separated JSON objects, which is not 100% compliant but works either way and is less memory intensive than creating a massive JSON array, especially with the Streaming API. ↩
-
Moreover, optionally adding
bas part of the access mode argument in theopenclass indicates that the script should write in binary mode as opposite to text mode, which is uncommon in such scripts, but decodes already escaped Unicode characters. In this case, it is necessary to encode our JSON dump to UTF8 → by calling the method.encode("utf8"). ↩ -
The only other option to access historical tweets of someone’s timeline beyond the initial 3200 tweets, is to resort to text scraping (e.g. using Javascript to simulate scrolling down and python to scrape the AJAX-loaded tweets). If there’s a demand for an in-depth tutorial I will add an appendix blog for that eventually. ↩
-
Language uses BCP 47 language identifiers. Language of each tweet is machine-detected and not 100% accurate. Read more. ↩
-
Again, the Twitter Stream API has several limitations in regards to the amount of tweets returned per second. Neither does it allow more than one established stream connection at one time. The above script will be sufficient to retrieve a sizable dataset but unless we have access to the paid full firehose, there are no methods available to guarantee an exhaustive collection. ↩
-
CSV is another open data exchange format for storing records of data, with fields separated by a comma. It might be easier to visualize the format as a kind of Excel spreadsheet, and indeed, spreadsheet applications such as OpenLibre or Excel 2019 offer quite strong integration of the CSV format. ↩
-
Running this script on a dataset of tweets by a single account will produce a lot of unnecessarily repeated user data, for example. ↩
-
Even then, Excel has some issues with importing (CSV) files that contain long numerals such as tweet IDs: only the first 15 significant digits are interpreted, displaying the remaining digits as 0. The best solution would be to thus select Text for the relevant column formatting upon importing the CSV data. ↩
-
For two excellent and recent English language papers which utilize a form of quantitative analysis of Japanese tweets in order to strengthen their main arguments, see: Tamara Fuchs & Fabian Schäfer (2020): Normalizing misogyny: hate speech and verbal abuse of female politicians on Japanese Twitter, Japan Forum, DOI: 10.1080/09555803.2019.1687564, and Fabian Schäfer, Stefan Evert, and Philipp Heinrich (2017): Japan’s 2014 General Election: Political Bots, Right-Wing Internet Activism, and Prime Minister Shinzō Abe’s Hidden Nationalist Agenda, Big Data. 294-309. DOI: 10.1089/big.2017.0049. ↩