This short series of blogs chronicles the bare-bones required to conduct a basic form of social media analysis on corpora of (Japanese) Tweets. It is primarily intended for undergraduate and graduate students whose topics of research include contemporary Japan or its online vox populi, and want to strengthen their existing research (such as an undergraduate thesis or term paper) with a social media-based quantitative angle.
The purpose of this third blog and the next, fourth blog is to introduce the reader to the concept of natural language processing (NLP), to the techniques available for processing Japanese texts, and to some basic forms of quantitative content analysis that could be performed with that processed data. Concretely, in this third blog we will:
- Learn about natural language processing in a Japanese context,
- Set up the morphological analyzer MeCab and the neologism dictionary mecab-ipadic-NEologd,
- Install and set-up the quantitative content analysis tool KH Coder,
- Perform a rudimentary content analysis on a corpus of tweets collected with methods described in the previous two blogs.
Although this blog thus assumes that the reader has read part one and two of this series, it should also serve as a solid stand-alone introduction to setting up MeCab and the IPADic NEologd dictionary (as of writing still pretty much the de-facto canonical tools in academic scholarship applying a form of Japanese computational linguistics) and combining them with KH Coder.
Due to the nature of the field, parts of this tutorial will be rather technical and rely on having some basic experience working with the Windows command prompt or MacOS Terminal, but despite the complexity of the matter, there shouldn’t be much of a technical difficulty gap compared to the previous tutorials.2
Japanese Natural Language Processing
‘Natural language’ refers to the usage of language that has developed naturally over time among humans, encompassing methods of communication such as speech, written text and signaling. Natural Language Processing, then, is the field of developing how computers can understand and process such use of language in a cognitive way. Applications of NLP are seen anywhere ranging from AI assistants (such as Siri, Alexa or Google Assistant), to automatic translation (e.g. Google Translate), targeted advertising, and even in health-care.3
An important preliminary step in processing natural language computationally is to tokenize of language (also referred to as word segmentation). In other words, to break down language into smaller segments (tokens), with morphemes being the smallest unit of language having grammatical meaning that can be broken down to. The following step in the NLP pipeline is then to identify the grammatical and semantic meaning of each morpheme within the context of the text it belongs to; a process called part-of-speech tagging (POS tagging). This is easier to do when handling languages with clear cut semantic borders such as punctuation and space boundaries, but more challenging when dealing with ambiguous, agglutinative and non-segmented languages (such as Japanese).
Due to the nature of the Japanese language, those two steps commonly go hand in hand under the header of morphological analysis and are done at the hand of so-called dictionaries; corpora of texts with a part of speech tag-set processed by hand and/or through machine learning methods. There is some debate to the development of those dictionaries as well, depending on how coarse or fine-grained tokenization tags should be (i.e. should sakanafuraiteishoku 魚フライ定食 be seen as one token, as a combination of sakanafurai 魚フライ and teishoku 定食, or as sakana 魚, furai フライ and teishoku 定食?), as well as what rules are applied, and which sources should be used for new dictionary entries.4 Depending on the selected dictionary, different Japanese morphological analysis tools will then apply different POS tagging techniques5 – probabilistic methods being the most common6 – in calculating boundaries and contextual tags of a language sequence.
Having tokenized and POS-tagged texts (which can be further preprocessed with methods such as stop-word removal), we can now employ a variety of computer-assisted quantitative content and text analysis techniques suitable for social media, ranging from a very rudimentary keyword frequency analysis, to topic modeling based on coding tables, sentiment analysis and narrative network theory analysis (which will be demonstrated over the next few articles). Although there are several NLP frameworks available that offer limited support for the Japanese language (such as NLTK and SpaCy), it is crucial that the initial process of morphological analysis is tailored to our needs. This blog article will therefore expand on a set-up adequate for tackling social media content such as tweets.
Japanese morphological analyzing
Despite being discontinued for almost a decade, and although rapid developments have being made in Japanese NLP over the past few years, the morphological analyzer MeCab remains as of writing the fastest, most frequently used Japanese tokenizer | POS-tagger, and the only option we can use in combination with KH Coder. There are, however, several other highly promising Japanese NLP options in active7 development that should not be neglected (and for which I will write a more complete comparison of in the near future):
- Janome is a pure Python MeCab alternative with a decent post-processing analyzer framework and English language documentation.8
- Ginza is an all-encompassing Japanese NLP library based on the NLP library spaCy, the Universal Dependencies cross-linguistic annotation convention, and the Japanese morphological analyzer SudachiPy (the latter, a python flavor of Sudachi, being the actual alternative to MeCab).9
- Juman++, unlike MeCab and its predecessors, relies on recurrent neural networks (RNN) – a deep learning method – for its POS tagging rather than on token dictionaries. While much slower than Mecab + NEologd, it appears to have incredible promise in dealing with colloquial language and spelling inconsistencies, which will be particularly useful for processing social media content.
MeCab Installation
There are several options for installing MeCab, based on our set-up:
- Unix | Windows x86: the official installers for Unix and 32-bit versions of Windows.
- Windows 64-bit: An unofficial 64-bit installer (select mecab-64-0.996.2.exe).10
- Mac (JP): Haven’t tested this myself but installation seems fairly straightforward using brew.
Make sure to select UTF-8 as encoding option when installing MeCab; UTF-8 is required to guarantee compatibility with Python and the optional custom dictionary mecab-ipadic-NEologd.11 Upon completion, we should also add two references to our global system variables. On Windows devices, open System Utility in the control panel and click system variables:
First we should add a PATH reference to the folder containing the MeCab executables: select Path → edit → new → add the path to that folder (e.g. C:\Program Files\MeCab\bin). Next, we should add a global variable MECABRC, with a value pointing to (our mecab folder)\etc\mecabrc (e.g. to C:\Program Files\MeCab\etc\mecabrc). The Mecabrc file within contains configuration data for MeCab, including the path to the dictionary we will using.
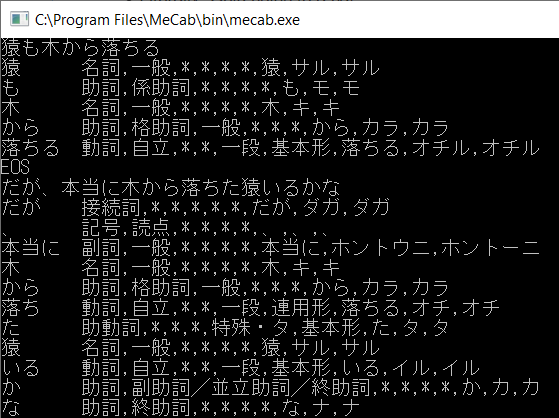 Figure 1: Example of MeCab + IPADIC POS-tagging of Japanese text
Figure 1: Example of MeCab + IPADIC POS-tagging of Japanese text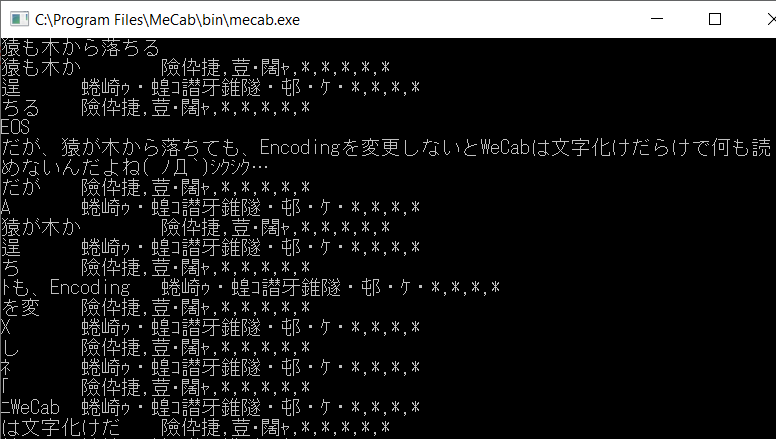 Figure 2: Example of encoding issues
Figure 2: Example of encoding issuesAs seen in Figure 1, MeCab probes the text-input at the hand of the selected dictionary (in this case the default IPADIC dictionary) in order to segment the Japanese text and return the grammatical and semantic meaning of each morpheme. The dictionary files (sys.dic and unk.dic) were pre-compiled based on a list of CSV files containing that grammatical and semantic information for most common morphemes. A closer look at any of those CSV files reveals a data structure according to the following column scheme:
Surface form (表層形), left context ID (左文脈ID), right context ID (右文脈ID), cost (コスト), part-of-speech (品詞), part-of-speech sub-classification 1 (品詞細分類1), part-of-speech sub-classification 2 (品詞細分類2), part-of-speech sub-classification 3 (品詞細分類3), conjugation type (活用型), inflectional form (活用形), original form (原形), reading (読み), pronunciation (発音)
Take, for example, the entry for tabero
食べろ,623,623,7175,動詞,自立,,,一段,命令ro,食べる,タベロ,タベロ は,14,,助詞,係助詞,,,,,は,ハ,ワ
The cost column indicates how likely the word is to occur (with a smaller number indicating a higher likelihood to occur). The context IDs are internal references to categories defined in the *.def files (specifically left-id.def and right-id.def) and classify the meaning of the morpheme within the text content seen either from the left or right (in this case, those IDs both refer to (動詞,自立,*,*,一段,命令ro,*). The other categories are self-explanatory: 食べろ, read and pronounced as タベロ,13 is the commanding ro conjugation of the dictionary form 食べる, an independent ichidan verb.
Note
After installing MeCab with the UTF-8 option, the MeCab default dictionary will have been recompiled with UTF-8 character encoding. Usually, running MeCab with the mecab.exe executable in (in /bin/) or by using the command (mecab) in the command prompt would allow usage as seen in figure 1. Depending on the character encoding of the console prompt (can be tested by using chcp), running MeCab as-is could result in encoding issues (see Figure 2), however. Having the Region Settings of the system locale set to Japanese, for example, would change the encoding (the code page) for console applications to code page 932 (e.g. Shift JIS).
Fortunately for us, there is hardly any use to running MeCab as-is; we’ll be running MeCab either with KH Coder or through Python scripts (which handles encoding for us). The above problem is therefore not of high importance and can nevertheless be by-passed with some simple workarounds.13
Finally, it should be noted that MeCab accepts several arguments in dealing with unknown words or for formatting output. This will be more relevant for the next part of this tutorial series, but for now, see figure 4 for a demonstration:
-d: path to one or more tokenizer dictionaries.-E: Which escape sequence to use at the end of the parsed string (tabs: \t, backspaces: \b, newlines: \n, etc.-O: Quick-formatting options. Wakati (short for wakachi-gaki, 分かち書き), for example, is a tokenizer option for returning a string with only the surface form of each token, separated by spaces.14-F: Grants us more control over the output formatting. Adding-F%m:\\t\\t%f[0]\\n, for example, will format the outcome as seen in figure 4: the token surface form and the first element of the ‘features‘ array (part-of-speech), separated by tab spaces.--unk-feature: set the return value of the part-of-speech column for unknown words (e.g. to ‘unknown‘ or to michigo ‘未知語’). Can be alternated with-x(e.g.-x 'unknown').
mecab-ipadic-NEologd installation (optional)
POS-tagging Japanese text on social media is particularly difficult due to the volatile nature of language usage on social media, including usage of neologisms and colloquialisms, as well as Japanese-specific usage of half-width characters, different Unicode characters and text emoji (kaomoji). The standard dictionary provided with MeCab, IPADic, hasn’t been maintained in over a decade and does not satisfy our needs. While optional, it is therefore highly recommended to install the neologism dictionary mecab-ipadic-NEologd, a MeCab dictionary expansion of the IPADic dictionary built using manual and machine learning methods on a wide variety of online texts. It contains a lot of entries of terms common on Japanese social media, as well as common names not yet belonging to the default MeCab dictionary (see figure 3 for a comparison when inputting prime minister Shinzo Abe’s name using respectively the default IPADic dictionary and the NEologd expansion).
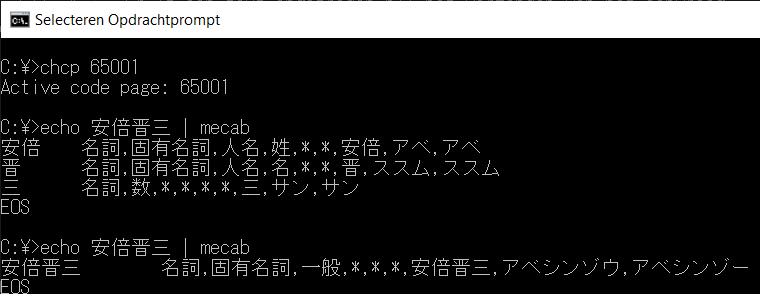 Figure 3: Parsed results of 安倍晋三 (Abe Shinzō) with respectively default and NEologd dictionary.
Figure 3: Parsed results of 安倍晋三 (Abe Shinzō) with respectively default and NEologd dictionary. Figure 4: Parsed text with various tokenizer settings.
Figure 4: Parsed text with various tokenizer settings.Installation of the Neologism dictionary is rather obtuse; as it requires us to manually build the dictionary based on our existing copy of the IPADIC dictionary and the source files for the NEologd expansion.15 This process is simple enough on Unix or Mac (as described on the project page), but less so on Windows. The following steps are, again, Windows-specific.
- The project-page for NEologd is hosted on GitHub and periodically updated. For those who have git installed, clone the project to a directory of choice with
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git. If not, select Clone or download → Download ZIP and extract to a directory of choice. - As mentioned earlier, MeCab dictionaries are compiled based on a list of CSV files containing grammatical and semantic information for each morpheme. We will need to recompile that dictionary based on the NEologd CSV files. Those CSV files are highly compressed as .xz files listed in the seed directory of the NEologd project folder. We will have to extract* those (select all the files with xz extension and extract them using 7zip or another file archiver of choice).
- Next, back in the ‘MeCab/dic’ folder make a copy of the ‘ipadic’ folder. Name it ‘ipadic-neologd’. As-is, the IPADic source files (the CSV and def files) remain encoded in EUC-JP (or SHIFT-JIS for older copies). The NEologd CSV files, however, are encoded in UTF-8. Compiling those together will lead to inconsistencies; we should therefore change the character encoding of the IPADic source files to UTF-8 as well.
Note
This can be done manually with most advanced text editors, or in bulk with iconv (part of GNUWin32).16 For the sake of convenience, this tutorial provides the re-encoded files on a dedicated GitHub repository. Simply download the repository as zip file and extract those files in the ‘ipadic-neologd’ folder to replace the previous copies.17
Finally, move the previously extracted NEologd CSV files to the ‘ipadic-neologd’ folder. We can now compile our IPADic-NEologd dictionary from the command prompt by changing to that directory and running mecab-dict-index with encoding set both from and to UTF-8:
1 2 | |
Note
If a reading error occurs, open the folder ‘/bin/’ (e.g.’C:\Program Files\MeCab\bin’), right-click mecab-dict-index.exe → settings → compatibility → check “run as Administrator”, and try again.
From here, edit MeCab’s settings to point to the IPADic-NEologd dictionary instead of the default IPADic dictionary. To do so, open the mecabrc file in ‘MeCab/etc/’ with a text editor and change dicdir to the relevant path (e.g. C:\Program Files\MeCab\dic\ipadic-neologd\).
mecab user dictionary (optional)
It is likely that during close readings of the texts we’re analyzing, new, specific terms will come up that are not yet part of the IPADic and NEologd dictionaries. Or perhaps we’ll be dealing with application-oriented text classification. As an example, and although it falls more under NER processing,18 one project19 involved a dictionary consisting of Japanese book titles generated from a bibliographic database. Their pipeline involved processing incoming tweets from the Twitter Streaming API with MeCab,20 building a database of tweets containing tokens of bibliographic nature.
On top of the system dictionary we have compiled with the above methods, MeCab permits additional user-generated dictionaries:
- Create a CSV file with terms formatted according to the data structure and column scheme seen above and save it a convenient folder. In our case, a user.csv file, saved in ‘MeCab\dic\ipadic-neologd\user', containing one row
旦那ストレス,,,1234,名詞,固有名詞,一般,*,*,*,旦那ストレス,ダンナストレス,ダンナストレス. - Open the command prompt. Navigate (
cd) to the folder containing the system dictionary (e.g. MeCab\dic\ipadic-neologd) and run mecab-dict-index with the parameter -u set to the output dictionary: e.g.mecab-dict-index -u user\user.dic -f utf-8 -t utf-8 user\user.csv. - Finally, open mecabrc with a text-editor and add a new variable
userdic, pointing to one or multiple dictionaries (separated by comma): e.g. userdic =C:\Program Files\MeCab\dic\ipadic-UTF8\user\book_titles.dic,C:\Program Files\MeCab\dic\ipadic-UTF8\user\emoji.dic.
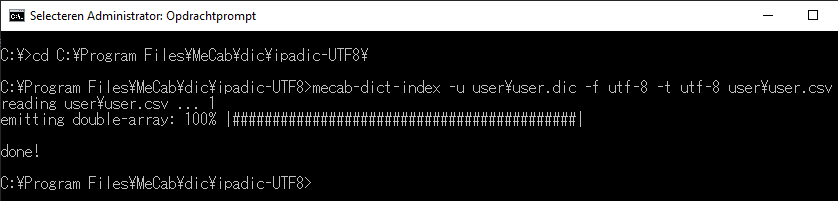
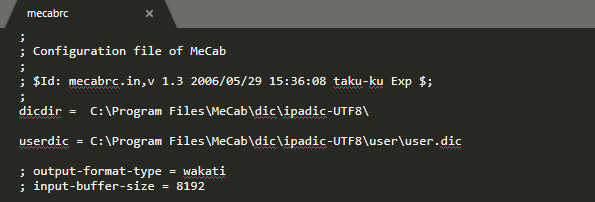
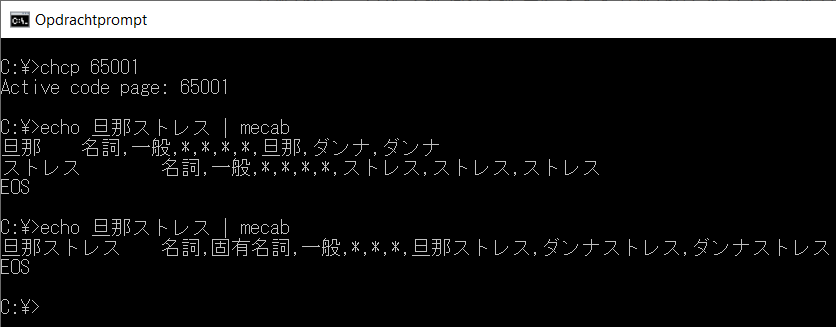 Figure 5: 安倍晋三 (Abe Shinzō) with NEologd dictionary.
Figure 5: 安倍晋三 (Abe Shinzō) with NEologd dictionary.Note
The cost field above was filled in randomly. While not harmful when dealing with very specific terms, doing so with a very large dictionary can obviously mess with our results. For a guide on estimating the cost, read コストの自動推定 (JP).
Normalizing Japanese text with Neologdn (optional)
Within the context of NLP, normalization refers to the process of converting words to their ‘canonical’ form or implied meaning, regardless of its spelling (usage of upper- and lowercases, acronyms, alternative spellings, misspellings, etc). Like stemming or lemmatization (reducing words to their root form by removing inflection), this should be done on a case-by-case basis. In the Japanese language, for example, りんご、リンゴ and 林檎 (ringo) are all common notations for the word ‘apple’.21 Likewise, 可愛い, かわいい, カワイイ and even カワ(・∀・)イイ!! (kawaii) all mean ‘cute’, but – unlike the rather neutral variants for apple – differ slightly in demographic usage.
Normalizing Japanese text with mixed spellings of kana and kanji is a complicated process.22 for now, however, this small library consists of several regular expressions already helpful in normalizing common tendencies of Japanese text on social media, such as converting half-width characters to full-width. As always, install with pip: pip install neologdn.
KH Coder
KH Coder is an open-source tool for performing quantitative content analysis, both by conducting statistical analysis on the whole set of text, or by applying coding rules and categorizing pieces of text. Although KH coder supports a variety of other languages (using the Stanford POS tagger), KH Coder was originally written with the Japanese language in mind and supports both ChaSen and MeCab. Having taken the above steps, we can now conduct analysis with KH Coder using a tokenizer and POS-tagger that should be more suitable for dealing with social media content.
KH Coder can be downloaded from the link above. I wholeheartedly recommend to view the author’s powerpoint slides as well as read both of his publications on how to apply KH Coder for the purpose of quantitative content analysis.23
Preparing tweet content: python
Before we start with KHCoder, however, let’s build a CSV file based on the CSV file of (re)tweets generated in the previous article. This new CSV, consisting of two columns (the tweet text and its author), will have such artifacts as hashtags and user mentions removed. Our script (as usual, available for download on GitHub), thus look as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | |
Note
Similar to the scripts provided in the previous tutorials, the script above should be saved in the folder we have used thus far to store the rest of our script files (e.g. ‘C:\python_examples‘ → ‘python_tweet_content.py’). The script takes two argument: the name of the input CSV file and the name of the save-file. The commands used to execute our script could thus respectively look like: python python_tweet_content.py #旦那ストレス danna (output CSV files are stored in the same folder as the input CSV, e.g. ‘results/旦那ストレス_tweet_content.csv’). That latter step is necessary because KH Coder only accepts files with ASCII file-names.
On that matter, KHCoder only supports EUC and SHIFT-JIS encoded text-files. Thus far we have been encoding our files as UTF-8. While obtuse, lines 28 and 35 are necessary steps to re-encode that content.
Using KH Coder
Having started KH Coder, let us first change some settings. Click Project → Settings, and make sure ‘MeCab’ is selected as method for Word Extraction and the path refers to the correct executable.24 Furthermore, make sure Unicode Dictionary is checked: we are using a Unicode (UTF-8)-encoded dictionary.
Next, click Project → New, and select the CSV file we extracted using the script above (make sure Japanese and MeCab are selected as language and POS-tagger). From there, click Pre-Processing → Run Pre-Processing (this might take quite a while depending on the size of the file). If everything went well, we can now conduct statistical analysis and produce various visualizations that offer quantitative insights in the corpus of tweets we collected.
Stop-words (optional)
Stop-words refers to the most commonly used words in natural language; words we might want to filter out of our corpora depending on the context. Although we have done some filtering of noise already, figure 7 reveals suru する (an irregular verb meaning to do, often used in combination with compound verbs) and nai ない as some of the most frequent lemmas. Another (or complimentary) method to remove such elements from textual content is thus to make use of stop-word lists.
I will write an extended blog post about how one might generate a Japanese language stop-word list, but for now I recommend this one.25 Simply save in a convenient location and open with a text-editor of choice. Add an extra row “—cell—” (necessary for KH Coder’s inner workings) and an extra row “ー”. Next, in KH Coder, click Pre-Processing → Select Words to Analyze → force ignore. Mark the Read from a file check-button, and click browse to select the above stop-word list. Finally, run pre-processing again.
Note
The usage of the Japanese ー in informal online language is to extend vowels (e.g. しかーし → しかーし) or to flatten consecutive vowels in a way that sounds more rough (e.g. うるさい → うるせー). Neologd does includes many terms that are abbreviated in such matter (知らねー) which are then normalized to the root form (知る), but does not, for example, process variations using both ー and small kana to extend the same vowel (知らねぇー、じゃねぇー,スゲェー), as well as various exclamations like はぁー. In those cases, ー is wrongfully tagged as a proper noun.
This behavior actually stems from MeCab’s default behavior in trying to identify and tag unknown words. Running MeCab with the unk-feature parameter set helps in that we can choose to tag unknown words as such. Unfortunately, KH Coder is built around MeCab’s ChaSen output (using the ‘-OChasen’ parameter), and changing this requires rewriting a lot of the inner workings of KH Coder. An easier option is thus to just add words that clearly do not add value to the force ignore list.
Analysis
As an illustration, this article uses a corpus of Japanese tweets containing the hashtag #
The focus on that particular hashtag took place within a larger discussion – as part of a BA project – of the COVID-19 crisis and gender hegemony in Japan. One question that came up was whether Twitter users were using those hashtags as means of forming communities of self-empowerment, or instead resorted to using the medium as a form of semi-public diary. Moreover, what were the main topics discussed in this corpus of collected tweets?
Frequency List
In order to navigate that question, one of the first steps we might do is generate a frequency list (see figure 6); by clicking Tools → Words → Frequency List, and generating a CSV or Excel file based either on the general Top 150 tokens or sorted by POS tags. This gives us not only a clear overview of the most frequent terms and thus of key topics, but also of possible errors occurring during tokenization (e.g. wrongfully parsed terms).
Having imported that file in KH Coder, we could immediately see that our corpus of 2,555 tweets consists out of 73,590 tokens (40,473 after stop-word filtering), with 7,914 of those unique terms (7,257 after stop-word filtering). A term frequency distribution (Tools → Words → Descriptive Stats), illustrated in figures 7 and 8, further reveals that about half of those 7,914 terms occur only once.
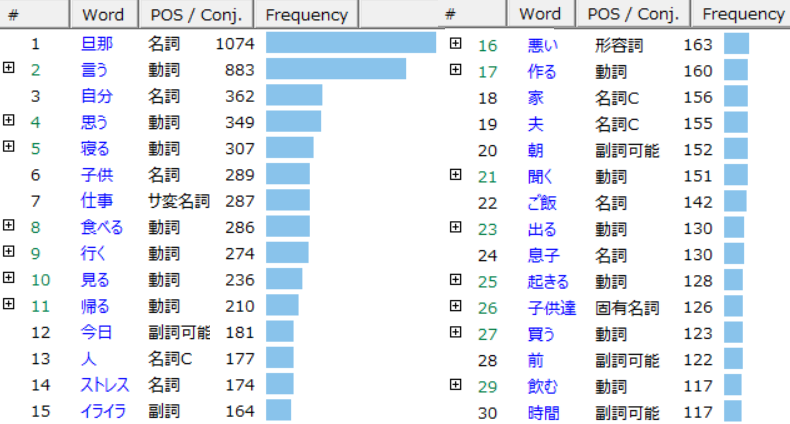 Figure 6: 30 most frequent terms.
Figure 6: 30 most frequent terms.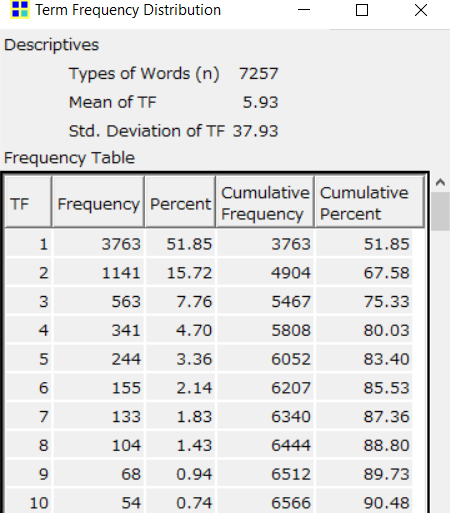 Figure 7: Term frequency distribution list.
Figure 7: Term frequency distribution list.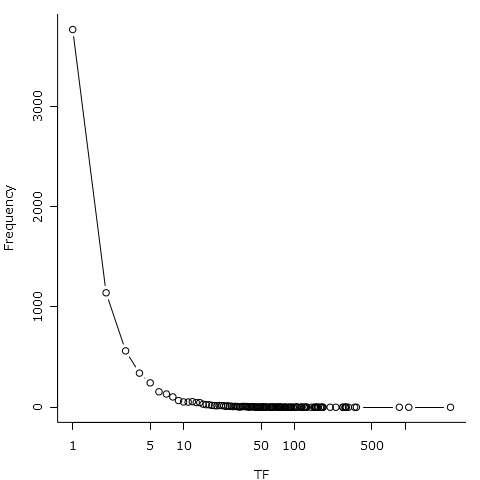 Figure 8: Term frequency distribution plot.
Figure 8: Term frequency distribution plot.There is not much else we take away from this information alone. It is not a particular surprise that the most common term is
Co-occurrence network
A co-occurrence network is a form of network analysis exploring co-occurring terms in our text. In other words, a visual network is formed based on the proximity of high-frequency terms (in non-inflicted form) as a means of identifying clusters of implied meaning.26 This could help to empirically reveal some of the major trends in these tweets. figure 10 (without stop-word list) and figure 11 (filtered of stop-words) are limited to words with a term frequency of 40 (accounting for about 2% or approximately top 150 most frequent terms, and approximately 40% of all terms) and of all POS-categories excluding grammatical ones such as joshi 助詞 and hitei jodōshi 否定助動詞 (negating auxiliary verbs such as zu ず and nu ぬ). Both figures are based on the top 50 combinations of proximity, while figure 12 and the interactive HTML variant thereof, figure 9, take only combinations with a similarity coefficient of 0.1 or higher.
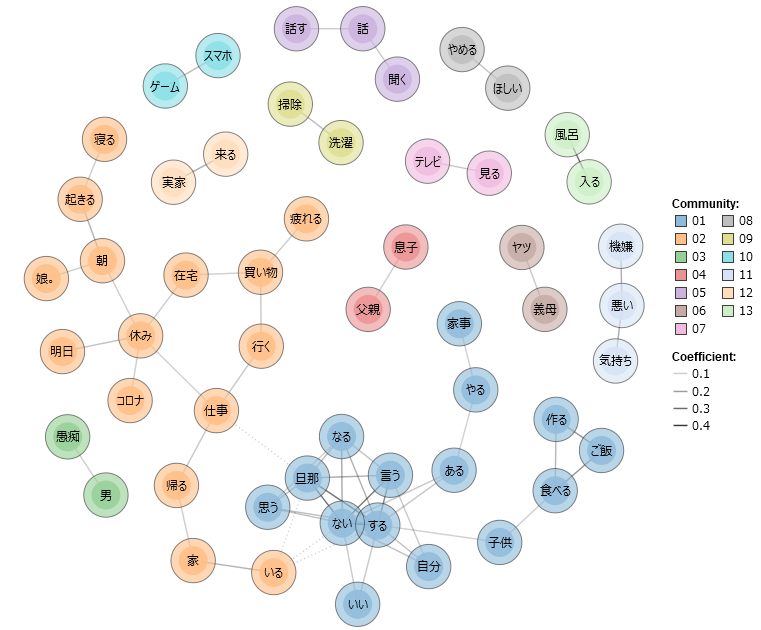 Figure 10: co-occurrence network of TF => 50 & top 50 combinations of proximity (unfiltered).
Figure 10: co-occurrence network of TF => 50 & top 50 combinations of proximity (unfiltered).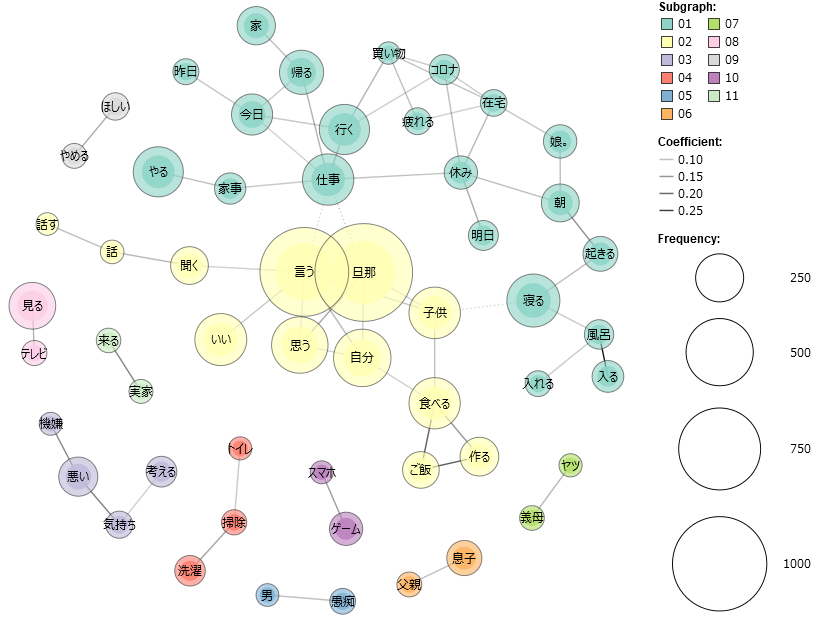 Figure 11: co-occurrence network of TF => 50 & top 50 combinations of proximity (filtered by stop-word list).
Figure 11: co-occurrence network of TF => 50 & top 50 combinations of proximity (filtered by stop-word list).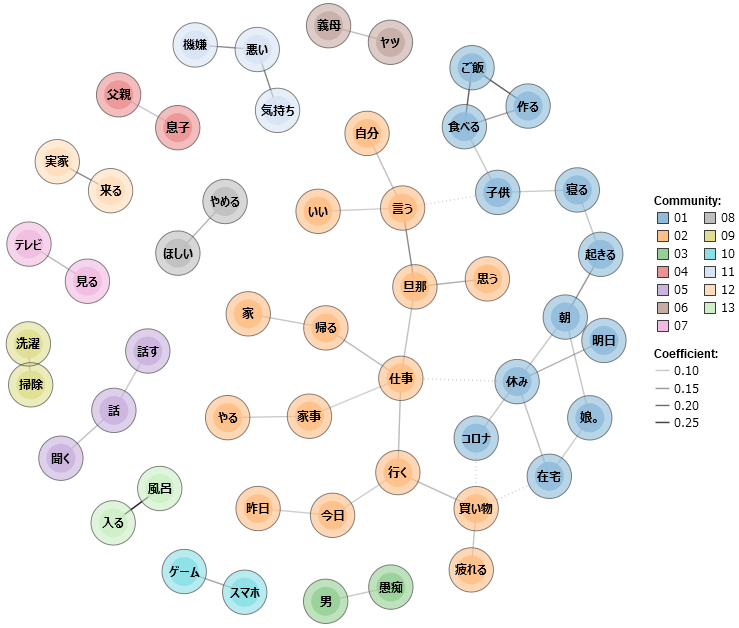 Figure 12: Co-occurrence network of TF => 50 & similarity coefficient => 0.1 (filtered by stop-word list).
Figure 12: Co-occurrence network of TF => 50 & similarity coefficient => 0.1 (filtered by stop-word list).KWIC concordance
Clicking on any of the terms in the co-occurrence network in KH Coder opens the KWIC concordance screen,27 revealing all the tweets containing that particular term as well as the closeness of other frequent terms.
A big trend among these posts seems to be the frustration of the tweet users towards the lack op cooperation of their husband in daily housework – cleaning, laundry, cooking, taking care of children, groceries – as well as lack in assisting with parental duties, lack of hygiene and lack of communication. This happens on top of the COVID-19 crisis leading to measures such as remote work or temporary unemployment. Take, for example, the following three randomly selected and translated tweets based respectively on the terms ‘corona’, cleaning’ and ‘bath’:
“Being in the same room, on top of the stress of self-quarantining during the Corona-crisis, is just too difficult.”
“A week of vacation during Golden Week. During that time I worked 4 days. Regardless of the holidays, a housewife operates as usual: cooking, cleaning, laundry, playing with children… During that time, my husband did nothing but playing on his smart phone or reading manga. Even if I ask him to play with the children, it’s impossible…”
“In spite of working in the service industry, you come back home and fall asleep in the sofa without washing your hands or taking a bath? I told you to take a bath when coming back. Even if I ask several times, after one or two days it’s back to usual. We have three children and we all use that sofa. Don’t undo our effort to self-quarantine!”
Coding topics
Judging from the above information, we could identify several topics: children, household tasks, the novel corona-virus, family-in-law, … Based on the term frequency information we obtained through the methods above, a very rudimentary coding dictionary of terms that align with those topics was thus created:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Saving the above file and applying it as coding rule against the corpus (Tools → Coding → Frequency → H5) reveals how many tweets contain keywords that we have coded among the above categories (as seen in Figure 13).
Considering the origin of the corpus, it is safe to say that the majority of tweets will contain grievances concerning the Twitter user’s husband. Indeed, over a quarter of those posts contain harsh, aggressive language. Posts that directly reference COVID-19 (about 5%) or even the employment status of the husband (approx. 15%), however, are relatively low in numbers. The most prevalent category is that of household tasks; confirming the likelihood that these users are using the medium to vent daily frustrations in regards to the labor performed as a housewife and the lack of compassion or assistance from the husband; something that is further aggravated due to the virus.
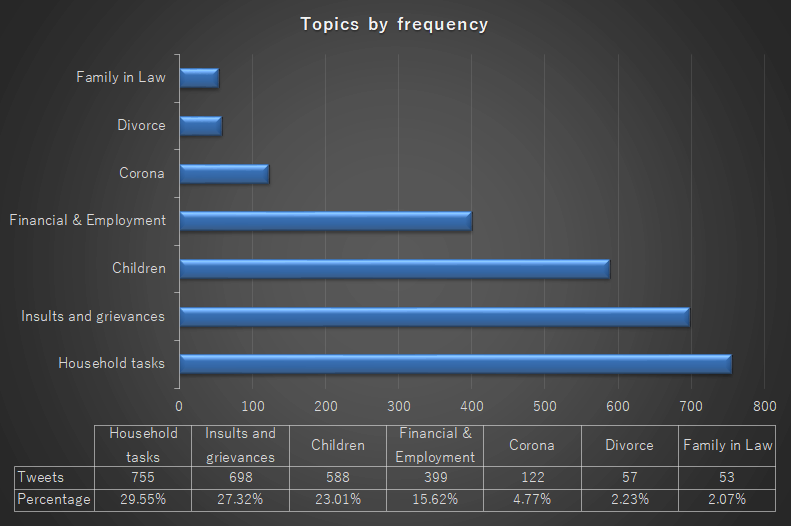 Figure 13: Topic frequency.
Figure 13: Topic frequency.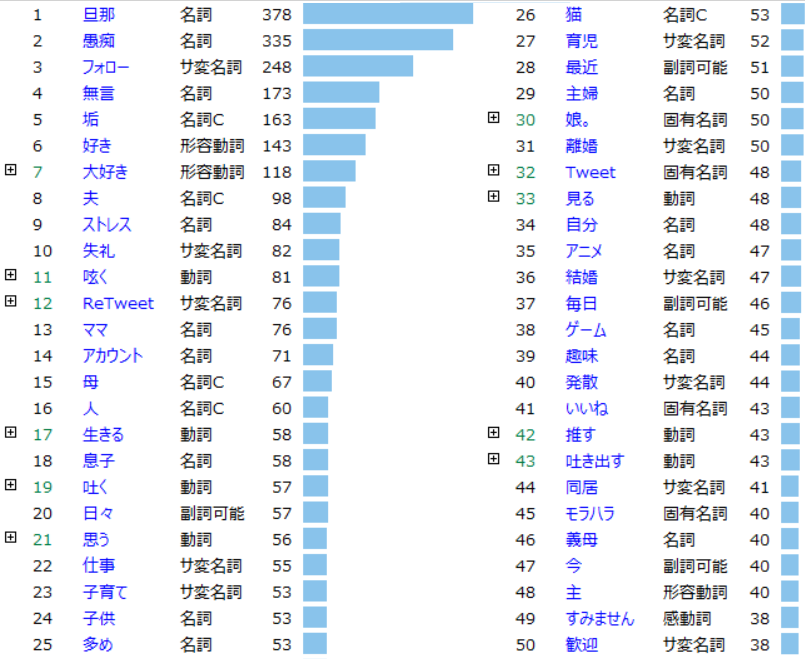 Figure 14: Term frequency of user description corpus.
Figure 14: Term frequency of user description corpus.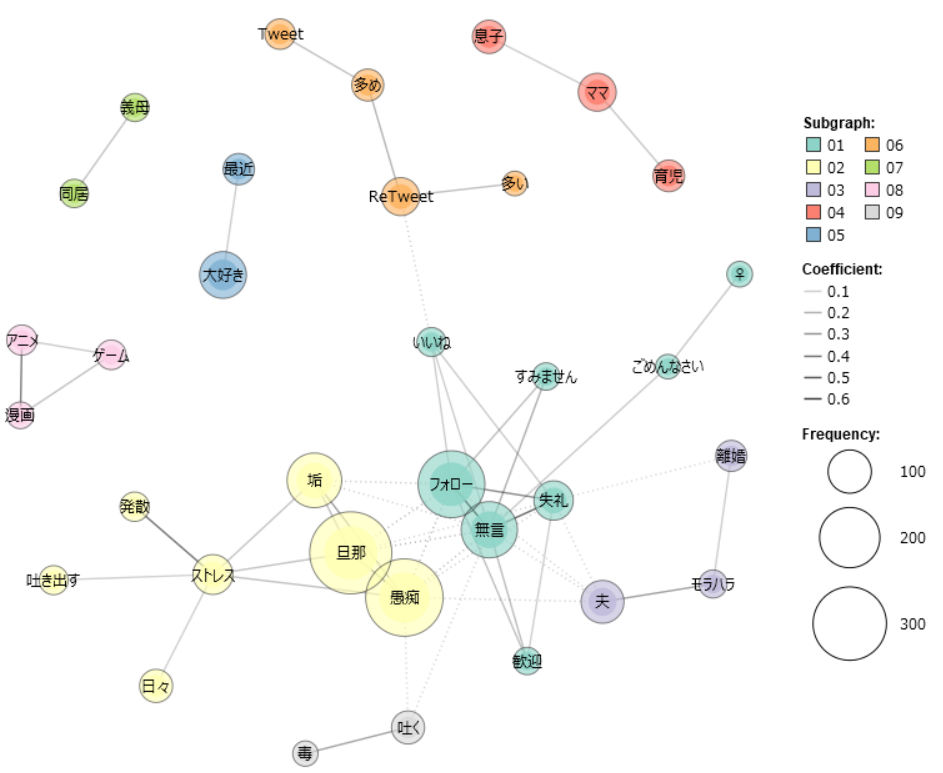 Figure 15: Co-occurrence network of of user description corpus (TF > 30 & Coef. >= 0.10).
Figure 15: Co-occurrence network of of user description corpus (TF > 30 & Coef. >= 0.10).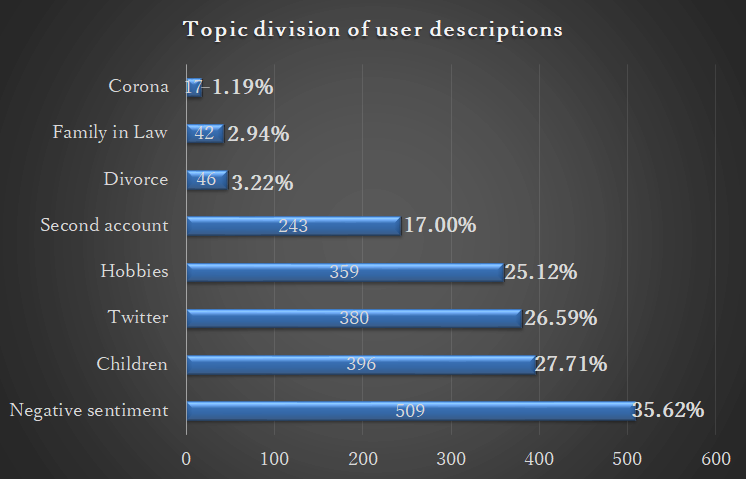 Figure 16: Topic frequency of of user description corpus.
Figure 16: Topic frequency of of user description corpus.Finally, we might want to apply the same methods on a corpus of the personal description of Twitter users to gain more insight into the behavioral patterns of those engaging with the #husbandstress hashtag. The following data is based on a list of user profiles that have posted at least one tweet with that hashtag (a total of 1,429 profiles), filtered by the same standards as above. Figure 15 and Figure 16, in particular, shows several trends among those users:
- Nodes that refer to personal hobbies or things those users might be interested in lately, such as animation and video games (something for which NEologd is particularly useful),
- The personal identity marker of being a mother,
- Complaints concerning the husband, with the related possibility of a divorce, as well as reference to living together with the mother-in-law.
- The usual Twitter structures such as mugon forō shitsureishimasu
無言 フォロー失礼 します (“forgive me for following without saying anything”); implying that many users will use the account to follow others, possible in similar situations, without the secondary purpose to communicate with each other, - References to the purpose of the Twitter account: a second account intended to express daily grievances.
“My husband is just impossible. I am comforted by seeing the tweets of people expressing the same stress.”
“I feel murderous rage towards my husband and parents-in-law. This is a complaints-account. Forgive me for silent-following.”
“Account dedicated to complaining about my husband. I want someone with whom I can freely share such complaints.”
“I only write complaints about my husband. I am 9 months pregnant and have one 3 year old child. I like Arashi and Korean dramas. Sorry for silent-following. Feel free to do so yourself.”
To do
The above analysis is of course a mere illustration of how these tools could contribute towards a quantitative content analysis approach on Japanese tweets. There are various issues remaining in the above example, including a lack of taking into account the general weighing impact of disproportionately frequent tweeters, a too rudimentary topic coding, a lack of theoretical base and, as is common in criticism on content analysis, perhaps too liberal or reductive an interpretation of co-occurring high-frequency terms. It is recommended that BA and MA students interested in applying these techniques delve further into the methodology of content analysis as well as look up other, published examples utilizing MeCab or KH Coder.
Wait! There is more!
This brief tutorial offered a brief introduction to natural language processing in Japanese context as well as some of the tools available, such as KH Coder. Yet, while the graphical user interface of KH Coder and its plethora of statistical analysis options provided are definitely valuable for in-depth quantitative content analysis, in our next post we will be looking into the benefits of dedicated NLP tools for Python and apply a more extensive method of Japanese normalization.
- A
QuickGuide to Data-mining & (Textual) Analysis of (Japanese) Twitter Part 1: Twitter Data Collection - A
QuickGuide to Data-mining & (Textual) Analysis of (Japanese) Twitter Part 2: Basic Metrics & Graphs - A
QuickGuide to Data-mining & (Textual) Analysis of (Japanese) Twitter Part 4: Natural Language Processing With MeCab, Neologd and NLTK - A
QuickGuide to Data-mining & (Textual) Analysis of (Japanese) Twitter Part 5: Advanced Metrics & Graphs
On a final note, it is my aim to write tutorials like these in such a way that they provide enough detail and (technical) information on the applied methodology to be useful in extended contexts, while still being accessible to less IT-savvy students. If anything is unclear, however, please do not hesitate to leave questions in the comment section below.
-
Still image from the 2012 Japanese animated film Wolf Children by Mamoru Hosoda, used under a Fair Use doctrine. ↩
-
Again, this tutorial is Windows-centric. It provides some guidelines for Mac users, but those steps have not personally been tested. ↩
-
This is of course based on my own limited understanding; entire degrees are set up around those fields. For serious research projects (such as during a graduate thesis), it might be worthwhile to contact someone from the local Digital Humanities department. For a general introduction to NLP, Your Guide to Natural Language Processing (NLP) is a good article to start with. Finally, for a more general introduction to Japanese NLP and computational linguistics, I recommend the free introductory chapter (available here) of Bond, F. et al’s 2016. “Readings in Japanese Natural Language Processing”. ↩
-
For a brief overview of the various dictionaries available for Japanese NLP, read An Overview of Japanese Tokenizer Dictionaries. ↩
-
For a brief overview of POS-tagging methods, read NLP Guide: Identifying Part of Speech Tags using Conditional Random Fields. ↩
-
As pointed out in this Quora thread, ChaSen used Hidden Markov Model (HMM) chains in its statistical calculation of probability and inferring relationships between each other. As outlined in this paper by the author of MeCab, MeCab uses Conditional Random Fields (CRFs), a probability model similar to Maximum Entropy Markov Models (MEMM). ↩
-
There are various others, such as ChaSen, JUMAN, Kuromoji and KyTea, but those haven’t been in development for a while and don’t bring anything extra to the table. CaboCha is sometimes incorrectly listed among them, but is actually a syntactic dependency analyzer using Support Vector Machines that works side by side with MeCab and is written by the same developer. Nagisa, another python-based ‘Japanese tokenizer based on recurrent neural networks’, looks promising but at this point doesn’t seem to have any benefits over its RNN alternatives such as JUMAN++. Stanford NLP is an encompassing NLP solution with recently added support for Japanese texts, based on the Japanese Google Universal Dependency Treebank, but I haven’t checked this out in further detail. ↩
-
Its dedicated promotional character, a little girl holding an eponymous janome (bullseye) umbrella, is pretty cute too. ↩
-
Moreover, Sudachi appear to be the only one among these to perform in-depth normalization of words with inconsistent spelling. ↩
-
Running MeCab on Mac, Unix or x86 Windows architecture is fairly straightforward. Running Mecab on x64 architecture, however, was rather complex and required users to edit and recompile the source code manually. For the sake of archiving or future reference, these different blog entries were helpful in lining out the required steps. Fortunately, as of 2019, another developer provided a forked 64 bit installer. ↩
-
An expansion of the IPADic dictionary. Although there is an NEologd expansion of the NINJAL-developed UniDic (an actively maintained dictionary upholding Universal Dependencies conventions), the coarse nature of the much-older IPADic in tokening might arguably be a better fit for this kind of project. ↩
-
While the particle は would, for example, return a reading of ha ハ and pronunciation of wa ワ. ↩
-
Unless we edit the source code manually and recompile the application, there is not much we can do to fix this at this point anyway. One workaround, as this Japanese blogger writes, is to set the output encoding of the command prompt to utf-8 using
chcp 65001and piping the Japanese query withechoto mecab (e.g.!#batch echo 猿も木から落ちる | mecab), or alternatively, to use another command line utility program such as git Git Bash. ↩↩ -
The other options are “
-O chasen” (to display the POS tagged tokens in ChaSen format), “-O yomi” (for displaying the reading of the token) and “-O dump” (the default options, dumps all information). ↩ -
As pointed out here, an alternative method is to compile NEologd as a user dictionary and to use it in conjunction with the standard UNIDic dictionary, rather than to compile the two in one system dictionary. ↩
-
Having installed iconv, we could do the following in our command prompt to encode all CSV files to UTF-8. Simply replace the originals with the ones in the child directory afterwards:
for %%a in (*.csv) do "C:\Program Files (x86)\GnuWin32\bin\iconv.exe" -f EUC-JP -t UTF-8 %%a > ./utf8/%%a. ↩ -
Because of the frequent updates and massive size of the raw NEologd CSV files, this tutorial won’t provide a compiled dic file, however. ↩
-
Named Entity Recognition; identifying and tagging tokens that are real-world objects (persons, locations, products, etc). The NEologd dictionary has some basic NER as part of the pos sub-classification. The entry for Belgium, for example, returns the following: “ベルギー,名詞,固有名詞,地域,国,,,ベルギー,ベルギー,ベルギー”. In other words, Belgium is classified as a noun → proper noun → region → country. ↩
-
S. Yada and K. Kageura. 2015. Identification of Tweets that Mention Books: An Experimental Comparison of Machine Learning Methods. Digital Libraries: Providing Quality Information: 17th International Conference on Asia-Pacific Digital Libraries, ICADL 2015, Seoul, Korea, December 9-12, 2015. Proceedings ↩
-
For a process like this that requires handling large amounts of incoming tweets per minute, speed is particularly of essence. MeCab is therefore the most appropriate option, as of writing. ↩
-
The Japanese term for such words with different written forms and spelling inconsistencies is hyōkiyure #
表記 ゆれ (or… 表記揺れ 🙃). ↩ -
For a brief overview of this problem and one potential solution, read, Ikeda, Taishi, Hiroyuki Shindo, and Yuji Matsumoto. 2016. ‘Japanese Text Normalization with Encoder-Decoder Model’. In Proceedings of the 2nd Workshop on Noisy User-Generated Text (WNUT), 129–137. Osaka, Japan: The COLING 2016 Organizing Committee. https://www.aclweb.org/anthology/W16-3918. ↩
-
KH Coder is a complex application with a broad variety of tools. The application of KH Coder highlighted in this article serve as a mere introduction, and I wholeheartedly recommend anyone interested in what it has to offer to read the full manual as well. ↩
-
The one we have installed earlier. KH Coder 3 comes with a version of MeCab pre-installed in khcoder3/dep which can be safely deleted. ↩
-
Another commonly used stop-word list is the one released by the developers of the SlothLib web library, available here. Stop words are calculated not just on term frequency in large example corpora but also by its relation with other (based on n-grams). For an extensive overview of manually calculating such a list in Japanese, see https://mieruca-ai.com/ai/nlp-stopwords/. ↩
-
A method of content-analysis first applied by psychologist Charles Osgood in his 1959 paper “The Representational Model and Relevant Research Methods”. KH Coder’s visual application is based on force-directed graph drawing algorithms known as Fruchterman–Reingold forces, a method developed by Fruchterman & Reingold in 1991. ↩
-
KWIC stands for Key Word In Context. A KWIC concordance shows a list of all the pieces of text containing a particular lemma (KH Coder performs a form of lemmatization by taking the base form of the lemma based on the MeCab dictionary employed: i.e. stripping conjugation of verbs). ↩